CECA had initial progress in the following research areas after nearly five years of development:
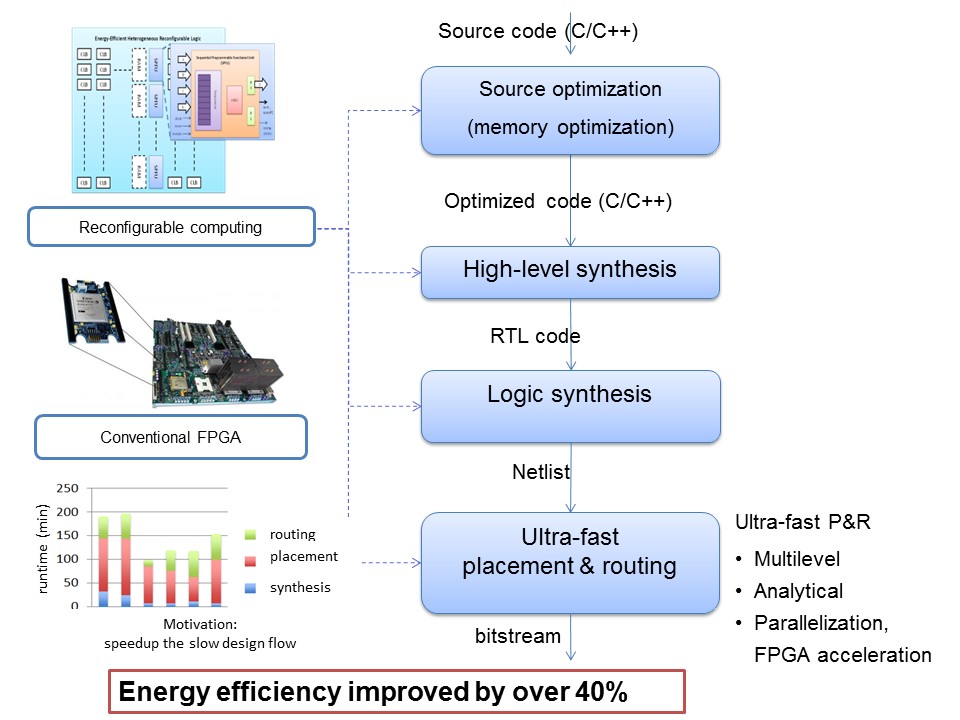
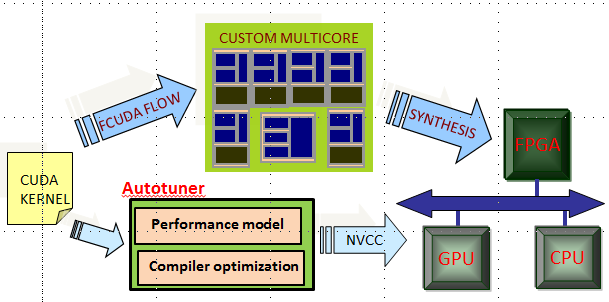
Compilation and Synthesis of Reconfigurable Accelerator-Rich Architecture: This project will design new algorithms in the automated flows, including high-level synthesis, logic synthesis, and P&R, for the accelerator-rich architecture based on FPGA or new reconfigurable fabrics. Besides, an open-source design flow will be released to facilitate the researches in this area. The major research topics include: (1) Programming model for FPGAs: The complex programming models of FPGA hinder its use in large-scale applications, and thus we propose to use parallel programming models for programming FPGAs. We choose Compute Unified Device Architecture (CUDA) as our programming model. On one hand, the thread model of CUDA represents parallelism. On the other hand, through CUDA, we can program the heterogeneous computing systems consisting of FPGAs, GPUs and CPUs. (2) Memory optimization in high-level synthesis. Multiple memory optimization techniques including data reuse, memory partitioning and memory merging as well as program scheduling and transformation using polyhedral model will be integrated into an automatic memory optimization framework. The algorithms will also be applied to novel reconfigurable architecture. (3) highly-scalable EDA tools, which will relieve the productivity lost due to the long compilation time. The goal is to design a P&R flow that is 10X-100X faster than the existing flow, using algorithmic acceleration, hardware acceleration, and parallelization. This project is partly supported by the National Natural Science Foundation of China and China Postdoctoral Science Foundation, and preliminary results have been published in ICCAD 2012, ASP-DAC 2012, ISPD 2012, ASP-DAC 2013, FPGA 2013, DAC 2013, FCCM 2014, FPT 2014, and ICCAD 2015.
Many-Core (GPU/MIC) Architecture and Compiler Optimization: Although GPU/MIC have been successfully used as accelerators to speedup various applications, the achieved performance speedup critically depends on the GPU/MIC compiler optimizations. This project focuses on the following optimizations: cache bypassing, concurrent kernel scheduling, sparse matrix-vector kernel, vectorization/SIMD optimizations. This project is supported by National Natural Science Foundation of China. Preliminary results have been published in ICCAD 2013, DAC 2014, TPDS 2015, CGO 2015, and HPCA 2015.

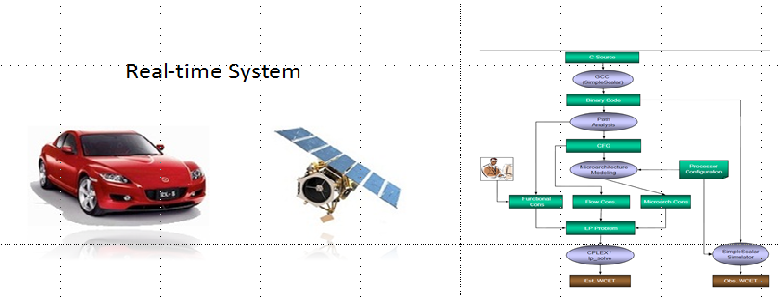
Compilation Techniques for Embedded Systems: Due to the safety nature of embedded/hard real-time systems, system designers need to obtain the worst case execution time (WCET) of a task via static program analysis. The WCET of a task not only depends on the control and data flow of the task, but also the underlying the architecture features such as caches. In this project, we propose to use cache locking in conjunction with static program analysis to improve the timing predictability for real-time systems. Preliminary results have been published in TECS 2013, DAC 2013, DATE 2014, and TCAD 2015.
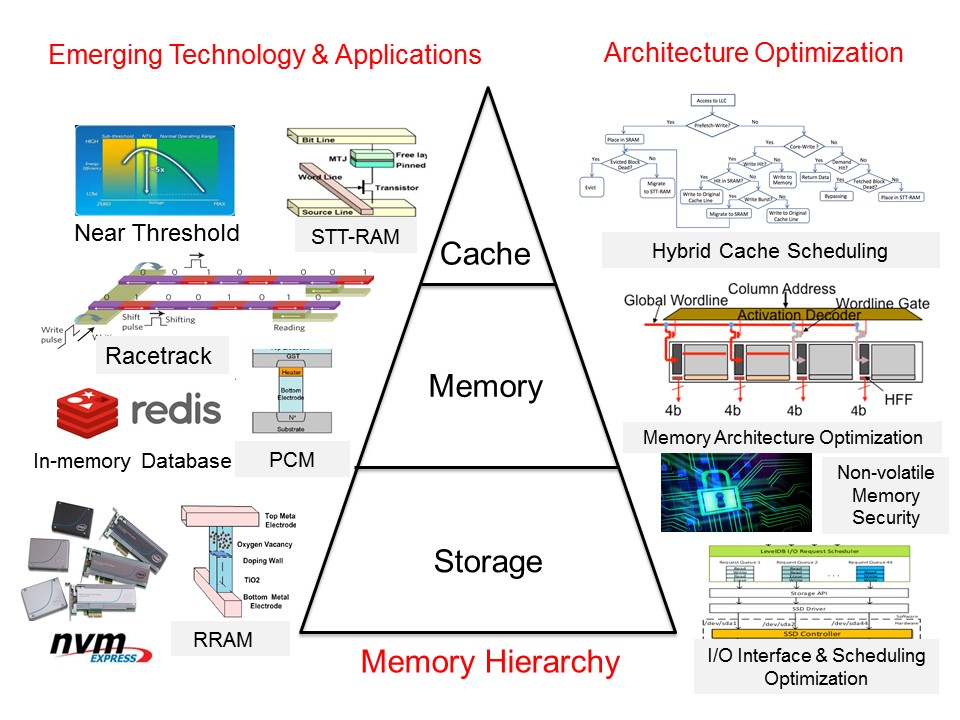
Architecture Exploration for Energy-efficient and Reliable Memory Hierarchy: “Memory Wall” has become a critical obstacle for development of modern computing systems. The traditional memory hierarchy cannot provide enough data to match the rapid increase of computing power. In this project, we mitigate this problem through memory architecture optimization, which includes following research topics: (1) Energy-efficient memory architecture based on emerging NVMs. Emerging NVMs have advantages of high density, low static power consumption, etc. At the same time they also have unique features, such as asymmetric-access, limited endurance, etc. Thus, we will optimize architectures and management policies based on their features to energy-efficiency. (2) Novel memory architectures for new applications. The new applications (e.g. in-memory computing/storage) have unique data access patterns. We will propose novel memory architectures dedicated for these new applications to significantly improve energy-efficiency. (3) With the scaling of memory technologies and adoption of emerging memory, reliability and security have become two design challenges for memory systems. We plan to improve both reliability and security through architecture level optimization. This project is supported by National Natural Science Foundation of China, National High Technology Research and Development Program (“863” Program), and Huawei. Preliminary results have been published in DATE 2012, ICCD 2013, ISLPED 2014, HPCA 2014, DATE 2015, ISCA 2015, ISLPED 2015, etc.
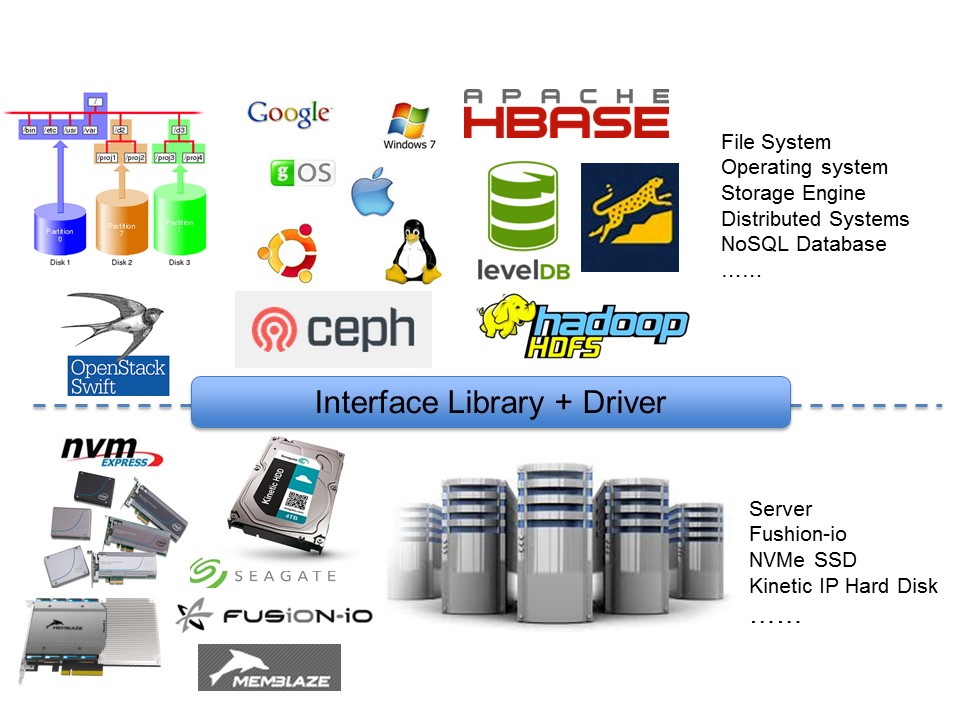
High Performance Storage Systems for Big Data Applications: As we have moved into the Big Data era, how to efficiently store and access the “big data” has become one critical challenge. In fact, the infrastructures of modern big data applications (e.g. Internet service) highly rely on powerful distributed storage systems, which have become key confidential techniques of leading Internet service companies. Recently, researchers from both academy and industrial have realized that conventional storage systems based on HDDs have become the performance bottleneck of modern computer systems. Consequently, various new storage devices (e.g. SSDs) have been widely adopted to improve I/O performance. However, conventional storage system designs, which were originally proposed for HDDs, cannot fully leverage advantages of these state-of-art storage devices. Thus, we plan to improve storage system and explore potential of these storage devices. First, we will optimize existing distributed storage systems (e.g. Ceph) to adopt these new storage devices. Second, we will modify and optimize current I/O stack in the level of OS and file system to facilitate adoption of these devices. Third, we will develop interface library to bridge storage engines (e.g. KV store) and low level drivers of these devices so that I/O performance is further improved. This project is supported by National High Technology Research and Development Program (“863” Program), Baidu, and Huawei. Preliminary results have been published in ISLPED 2013, ASPLOS 2014, EuroSys 2014, ISLPED 2015, MSST 2015, APSys 2015, APPT 2015, etc.
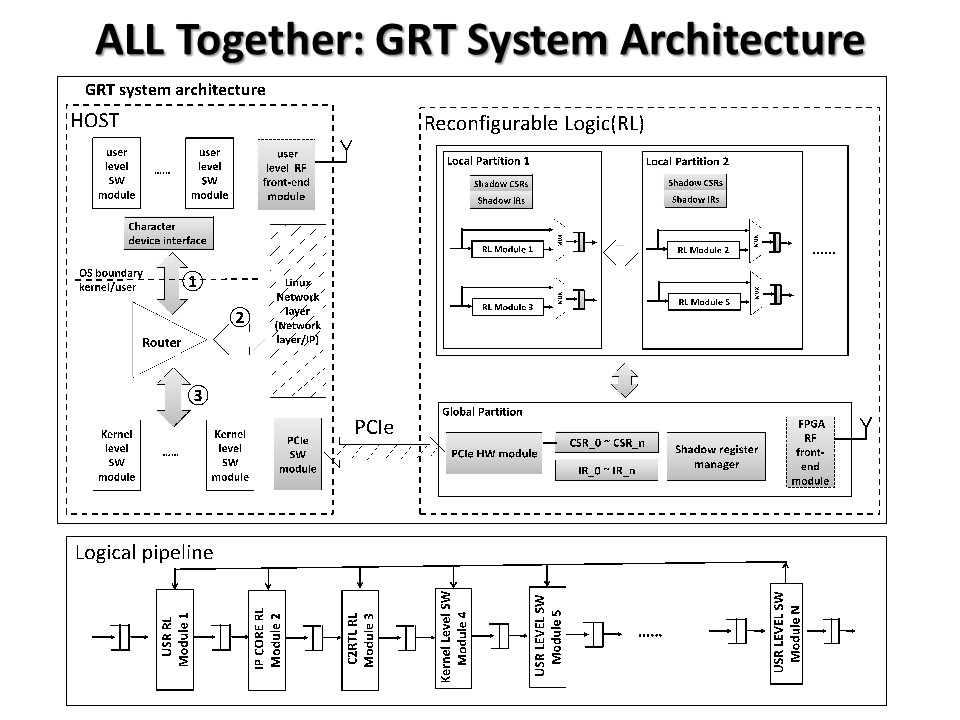
High-Performance Reconfigurable Architecture for Wireless LAN Physical & Data-link Layers: Wireless LAN (WLAN) technology has been widely employed in human’s life. The trends of higher data rate/energy-efficiency and rapid standard evolution pose higher requirements on the hardware architecture for physical and data-link layers. Researchers in both industry and academia are working hard to try to meet those requirements. We propose a novel high-performance reconfigurable architecture for WLAN physical & data-link layers, which can meet the high performance requirement within a reasonable power budget, and have three significant advantages: fast time-to-feature and longer life-cycle, much shorter developing cycle and lower developing cost, and efficient support for WLAN cross-layer optimizations. This project will have four research aspects: 1) the analysis on WLAN standards and the improvement on the algorithm stack; 2) the architecture design; 3) the programmability and compatibility of the architecture; and 4) the validation and prototyping of the architecture. By this project, we will get a novel trustable and efficient architecture design with front-end area/power data, as well as an open and friendly-used high-performance FPGA-based prototype system. This project has a very good application prospect in scientific research, national industry, and support for domestic processors. This project is supported by National Natural Science Foundation of China. Preliminary results have been published in MobiCom 2014, ACM SIGARCH Computer Architecture News (2014), FPL 2014, and ICFPT 2014.
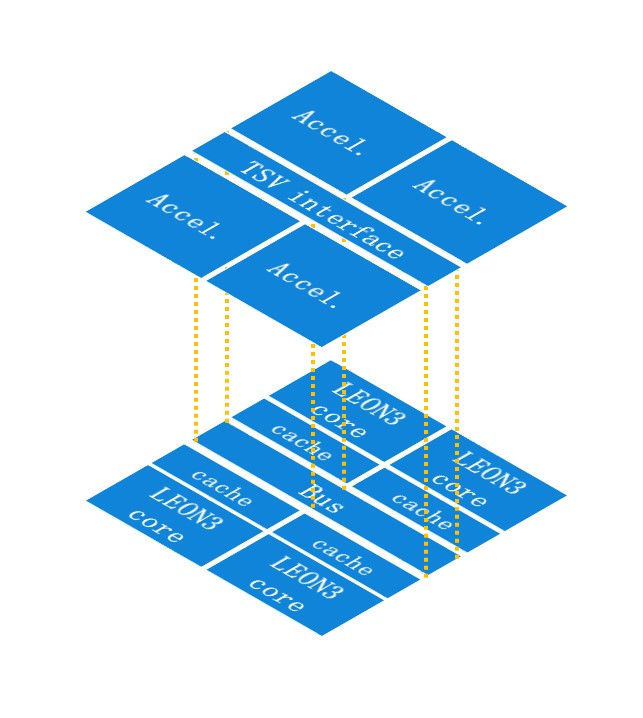
Design Automation for 3-D Integration and Low-Power Technologies: This project will solve the design issues on the generic many-core layer, the customizable accelerator later, the TSV-based communications, as well as automation tools for 3-D integration. The preliminary results show that this architecture provides 10+X improvement in energy efficiency compared to homogeneous many-core architectures. This project is supported by the Research Fund for the Doctoral Program of Higher Education of China. In addition, this project is also aware of the combination of low-power technologies and 3D integration. For example, we investigate the problem on using multi-bit flip-flops to reduce the clock power. We propose an analytical model for the multi-bit flip-flop clustering problem, which is able to reduce the clock power by 20% as the state-of-the-art, and further reduces the wirelength by 25%. These results were published in ISPD 2013 and ISPD 2015.
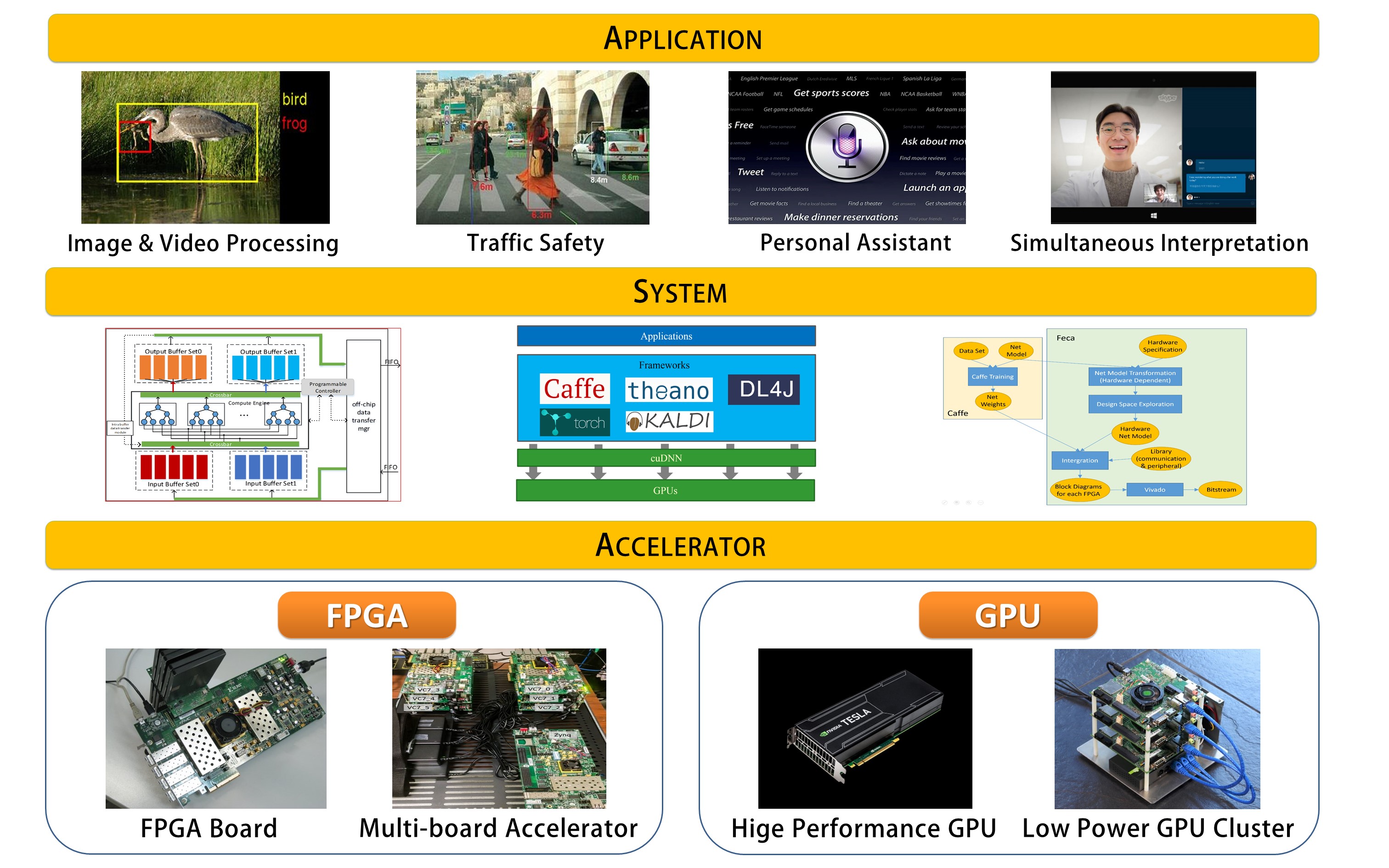
Energy-efficient Computing Systems for Deep Learning Applications: Recently, with the rapid development of computing systems and Deep Learning algorithms, researchers have achieved substantial progress in the field of machine learning. Deep learning algorithms have been successfully adopted in various applications, including image/video/audio recognition, NLP, etc. However, it is still inefficient to execute deep learning algorithms on computing systems based on generic processors. Though it is possible to improve computing performance though scaling up/out methods, these generic computing systems cannot satisfy energy, cost, or fingerprint constraints in various scenarios. Consequently, the heterogeneous computing systems based on GPU, FPGA, ASIC, etc., have been proposed as potential solutions. In this project, we plan to investigate system design and optimization for deep leaning applications in following three levels. (1) We will design proper accelerators targeting different design optimization goals. (2) Based on these accelerators, we will develop corresponding heterogeneous computing systems with consideration of performance, flexibility, and usability. (3) We will optimize existing deep learning algorithms to facilitate applying them on these heterogeneous computing systems so that energy efficiency can be further improved. Preliminary results have been published in SHAW-4, FPGA 2015, etc.
Acceleration for Medical Imaging: The advanced algorithms of medical imaging, including low-dose X-ray tomography and electron tomography, have high intensity in computation and strong requirement of real-time process. The Mumford-Shah regulation-based iterative method is able to obtain the reconstructed image and the segmentation simultaneously, and effectively remove the artifacts in the reconstructed image from a low-dose X-ray CT scan. However, the runtime of the iterative method is relatively long. We propose an asynchronous ray-parallel algorithm, and implement an effective pipeline structure on FPGAs. The FPGA implementation achieves a slightly better performance than GPU implementation, and improves the energy efficiency by 58X. Preliminary results have been published in SPIE Optics+Photonics 2015. Electron tomography reconstructs the 3D distribution of electronic absorption coefficient within an object using projection data obtained by electron microscope by rotating the specimen with various tilting diagrams. However, imaging resolution and field of view of current electron tomography is limited by the computational power. For example, using the state-of-the-art conical tilt method on a mainstream server with AMD Opteron 2.2GHz processor to reconstruct an image of size 1024 × 1024 × 128 takes 15 hours on average. This project builds hardware accelerators and software interfaces, to facilitate neuroimaging researchers and to design hardware-aware efficient tomographic algorithms.
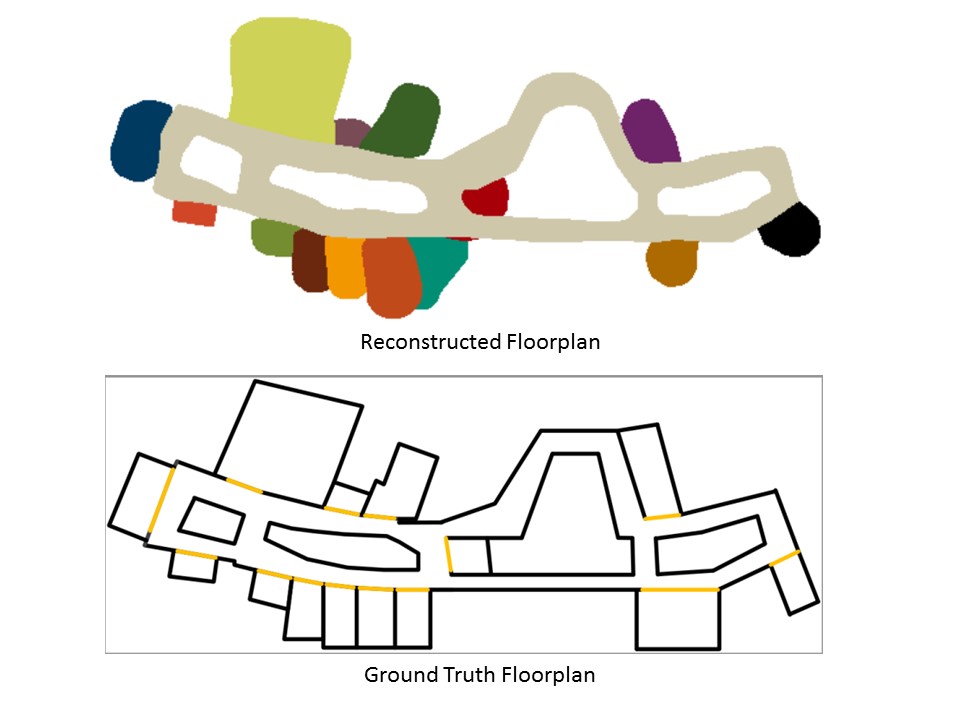
Localization based on Environmental Physical Features and Indoor Floor Plan Reconstruction Techniques: Indoor localization is the basis for many Location Based Services. Most of the current localization technologies rely on signals from certain IT infrastructure (e.g., WiFi, cellular tower). When the signal does not have sufficient strength or coverage due to obstacles or lack of such infrastructure, existing technologies cannot provide satisfactory localization accuracy. Additionally, service providers could hardly obtain the indoor floor plan easily. These two causes are major reasons why localization service is unavailable in most of the complex indoor environments worldwide. CECA studies how to leverage nearby fixed physical features (e.g., logos of stores in shopping malls, speed bumps in parking lots) to provide localization for smartphones through image matching, angle measurements, and motion sensor-based estimation in environments with little or insufficient IT infrastructure signal. We also leverage crowdsensed image and inertial data from mobile users, and reconstruct floor plan in complex indoor scenarios. This will make localization service widely available in all indoor environments. Preliminary results have been published in INFOCOM 2014, ICC 2014, MobiCom 2014, and SenSys 2015.
 weibo
weibo